Methodology
Data collection and processing
We gather, process, and analyse data from public reports of cyber incidents through a combination of data science tools and expert knowledge. Our data pipeline enables us to track and report changing trends in the global, and particularly European, cyber threat environment.
Our data pipeline:

The scientific coding of cyber incidents is an ongoing, iterative process. It necessitates continuous refinement and recalibration – for instance, adjusting intensity scores and attribution evidence. As fresh data is obtained, it is continuously incorporated into our existing dataset, which subsequently updates our interactive dashboard. In addition, we have strict coding procedures that mandate frequent assessment by both internal (secondary) and external reviewers.
Standardised and interdisciplinary coding
Using a standardised codebook, our team of experts in IT forensics, political science and international law assesses data on cyber incidents worldwide against a set of 60 criteria. For each incident, the following categories of information are recorded:

Scope
Cyber incidents in violation of the "CIA-triad of information security"
As a first technical requirement, a cyber incident must have violated the “CIA-triad of information security” to be relevant to our repository.
Cyber incidents that have been publicly reported
Second, our data covers only cyber incidents that are publicly reported, thus leaving out a potentially great number of unreported cases due to non-detection or nondisclosure.
Cyber incidents with a political dimension
Third, only cyber incidents that have a political dimension are included. This means cyber incidents that a) have affected political or state actors/institutions, b) have been associated with state-actors as the actual “masterminds” or exhibit a political motivation, or c) have been “publicly politicized, regardless of the affected target” (Steiger et al. 2018).
Cyber incidents against critical infrastructure
Finally, since February 2023, we also cover all cyber incidents against critical infrastructure entities, regardless of the attributed initiator, due to their increased threat situation.
This means that some cyber incidents are consciously cut out (e.g., many criminally motivated ransomware attacks against commercial entities) when they concern specific stakeholders but are not addressed particularly by political actors.
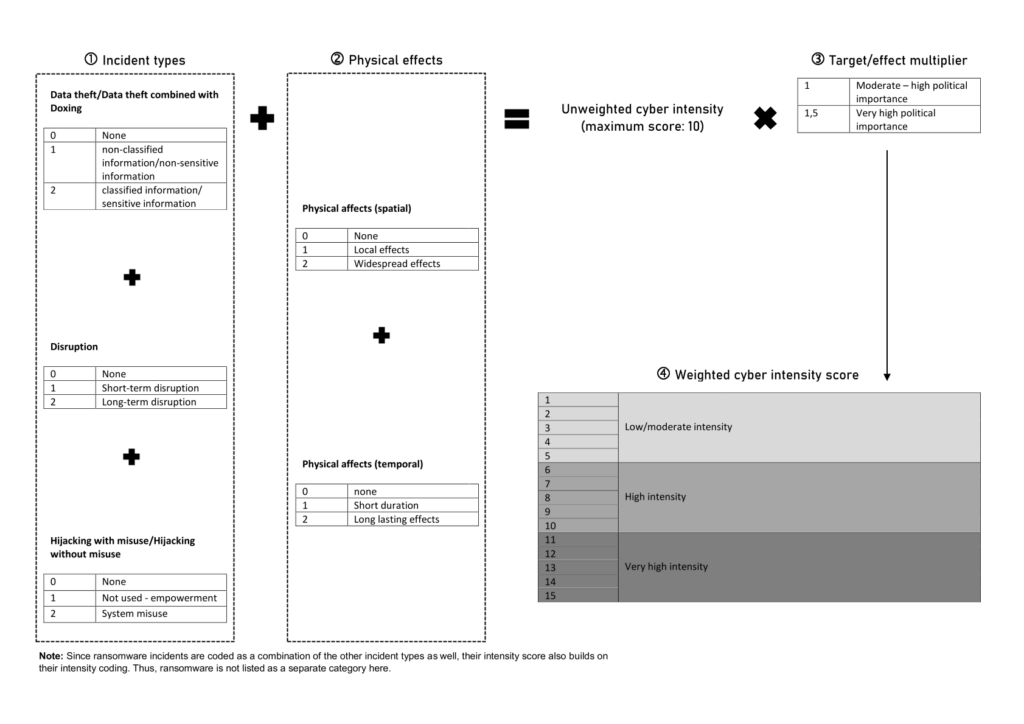
Cyber intensity indicator
Our Cyber intensity indicator measures the severity of a cyber incident. This is achieved by evaluating the duration of the incident itself and of its effects, as well as the criticality of targets. See our calculation method below:
Sources
| Source name | URL |
|---|---|
| ABC News | https://www.abcnews.go.com |
| Al Jazeera | https://www.aljazeera.com |
| AP | https://hosted.ap.org |
| AP News | https://www.apnews.com |
| Arab News | https://www.arabnews.com/tags/cybersecurity |
| ArsTechnica | https://arstechnica.com/ |
| Avast Threat Labs | https://decoded.avast.io/feed/ |
| BBC | https://www.bbc.com |
| BlackBerry | https://blogs.blackberry.com/ |
| Bleeping Computer | https://www.bleepingcomputer.com/feed/ |
| Bloomberg | https://bloomberg.com |
| Brisbane Times | https://www.brisbanetimes.com.au |
| Brookings | https://www.brookings.edu |
| Business Insider (DE) | https://www.businessinsider.de |
| Business Insider (EN) | https://www.businessinsider.com |
| Buzzfeed | https://www.buzzfeednews.com |
| C4ISR | https://www.c4isrnet.com/ |
| Canberra Times | https://www.canberratimes.com.au/ |
| CBC Canada | https://www.cbc.ca/ |
| CBS News | https://www.cbsnews.com |
| Channel News Asia | https://www.channelnewsasia.com/ |
| Channel News Asia [Cyber Security] | https://www.channelnewsasia.com/topic/cybersecurity |
| CISA ICS Alerts | https://www.cisa.gov/ |
| Cisco | https://blogs.cisco.com/ |
| CNBC | https://www.cnbc.com |
| CNET | https://www.cnet.com/topics/security/ |
| CNN | https://www.cnn.com |
| CNN Edition | https://edition.cnn.com |
| CNN Money | https://money.cnn.com |
| Computer World | https://www.computerworld.com/ |
| Corriere della Sera [Politics] | https://www.corriere.it/politica/ |
| Corriere della Serra | https://www.corriere.it/esteri/ |
| Cybereason | https://www.cybereason.com/blog/rss.xml |
| CyberGeeks | https://cybergeeks.tech/feed/ |
| CyberScoop | https://www.cyberscoop.com/feed/ |
| CybersecAsia | https://www.cybersecasia.net/news/feed/ |
| Daily Record EU | https://eu.dailyrecord.com |
| Dark Reading | https://www.darkreading.com/rss.xml |
| DataBreaches | https://www.databreaches.net/feed/ |
| Defense One | https://www.defenseone.com/rss/all/ |
| Der Standard [Inland] | https://www.derstandard.at/inland |
| Der Standard [International] | https://www.derstandard.at/international |
| Die Welt [Cyber] | https://www.welt.de/themen/cyberwars/ |
| Die Welt [Politik] | https://www.welt.de/politik/ |
| DPA International | https://dpa-international.com |
| Dragos | https://www.dragos.com/resources/?_block_resources_resource_type_filter=post |
| Economic Times India CIO | https://cio.economictimes.indiatimes.com/tag/cybersecurity/news |
| Economic Times India Telecom | https://telecom.economictimes.indiatimes.com/tag/cyber+security/news |
| Economist | https://www.economist.com |
| Eesti Päevaleht | https://epl.delfi.ee/kategooria/67583608/uudised |
| EFF Deeplinks | https://www.eff.org/rss/updates.xml |
| El Mundo [Espana] | https://www.elmundo.es/espana.html |
| El Mundo [International] | https://www.elmundo.es/internacional.html |
| El Mundo [Tech] | https://www.elmundo.es/tecnologia.html |
| El Pais | https://english.elpais.com/international/ |
| El Pais - Economy | https://english.elpais.com/economy-and-business |
| El Pais - International | https://english.elpais.com/international |
| El Pais - Science & Tech | https://english.elpais.com/science-tech |
| El Pais - Spain | https://english.elpais.com/spain |
| El Pais [Cybersecurity] | https://elpais.com/tecnologia/ |
| El Pais [Espana] | https://elpais.com/espana/ |
| El Pais [International news] | https://elpais.com/internacional/ |
| Euractiv | https://www.euractiv.com/ |
| Euractiv (news) | https://www.euractiv.com/news/ |
| Euro News | https://www.euronews.com/ |
| Euro topics | https://www.eurotopics.net/en/3/debates |
| F5 Labs Threats | https://www.f5.com/labs/rss-feeds/threats.xml |
| Financial Times | https://www.ft.com |
| Forbes | https://www.forbes.com |
| Fortiguard | https://www.fortiguard.com/resources/threat-brief |
| Fortune | https://fortune.com/ |
| Fox Business | https://www.foxbusiness.com |
| Fox News | https://www.foxnews.com |
| FoxIT | https://blog.fox-it.com/ |
| Frankfurter Allgemeine Zeitung [IT-Sicherheit] | https://www.faz.net/aktuell/technik-motor/thema/it-sicherheit |
| Frankfurter Allgemeine Zeitung [Politik] | https://www.faz.net/aktuell/politik/ |
| Gazeta Wyborcza | https://wyborcza.pl/0,173236.html#TRNavSST |
| Gazeta Wyborcza [National] | https://wyborcza.pl/0,75398.html |
| Gazeta Wyborcza [Technology] | https://wyborcza.pl/AkcjeSpecjalne/0,183960.html |
| Gdata | https://www.gdata.de/blog |
| Golem | https://www.golem.de/specials/security/ |
| Google Threat Analysis Group | https://blog.google/threat-analysis-group/rss/ |
| GovInfo Security | https://www.govinfosecurity.com/rss-feeds |
| Group-IB | https://blog.group-ib.com/ |
| Haaretz Israel News | https://www.haaretz.com/israel-news |
| Haaretz Middle East News | https://www.haaretz.com/middle-east-news |
| Haaretz Tech News | https://www.haaretz.com/israel-news/tech-news |
| Hackread | https://www.hackread.com/ |
| Heise | https://www.heise.de/ |
| Huffington Post | https://www.huffingtonpost.com |
| Huffington Post Feeds | https://feeds.huffingtonpost.com |
| Human Rights Watch | https://www.hrw.org/publications |
| Independent | https://www.independent.co.uk |
| Indian Express | https://indianexpress.com/about/cyber-security/ |
| Insight Crime | https://insightcrime.org/news/ |
| International Business Times | https://www.ibtimes.com |
| International Business Times Business | https://www.ibtimes.com/business |
| International Business Times World | https://www.ibtimes.com/world |
| Intrusion Truth | https://intrusiontruth.wordpress.com/ |
| IronNet | https://www.ironnet.com/blog/tag/threat-research |
| Japan Times | https://www.japantimes.co.jp |
| Jerusalem Post | https://rss.jpost.com/rss/rssfeedsinternational |
| Jerusalem Post Israel News | https://www.jpost.com/israel-news |
| Jerusalem Post Middle East | https://www.jpost.com/middle-east |
| Just Security [Cyber] | https://www.justsecurity.org/tag/cyber/ |
| Jylands Posten [International] | https://jyllands-posten.dk/international/ |
| Jylands Posten [Politik] | https://jyllands-posten.dk/politik/ |
| Kleine Zeitung [International] | https://www.kleinezeitung.at/international |
| Kleine Zeitung [Politik] | https://www.kleinezeitung.at/politik/index.do |
| Kleine Zeitung [Wirtschaft] | https://www.kleinezeitung.at/wirtschaft |
| Krebs on Security | https://krebsonsecurity.com/feed/ |
| La Repubblica | https://www.repubblica.it/tecnologia/?ref=RHHD-T |
| La Stampa [Esteri] | https://www.lastampa.it/esteri/ |
| La Stampa [Politica] | https://www.lastampa.it/politica/ |
| LA Times | https://www.latimes.com |
| La Vanguardia [Internacional] | https://www.lavanguardia.com/internacional/ |
| La Vanguardia [Politica] | https://www.lavanguardia.com/politica/ |
| La Vanguardia [Tecnologia] | https://www.lavanguardia.com/tecnologia/ |
| Lawfare Blog (Cybersecurity) | https://www.lawfareblog.com/topic/cybersecurity |
| Le Figaro [Bourse] | https://bourse.lefigaro.fr/ |
| Le Figaro [International] | https://www.lefigaro.fr/international |
| Le Figaro [Main] | https://www.lefigaro.fr/ |
| Le Monde [Cybercrime] | https://www.lemonde.fr/cybercriminalite/ |
| Le Monde [Security] | https://www.lemonde.fr/securite-informatique/ |
| Les Echos [Monde] | https://www.lesechos.fr/monde/ |
| Les Echos [Tech] | https://www.lesechos.fr/tech-medias/ |
| LookingGlass | https://lookingglasscyber.com/blog/ |
| Malwarebytes Labs | https://blog.malwarebytes.com/feed/ |
| Mandiant Resources Blog | https://www.mandiant.com/resources/blog |
| Microsoft On the Issues | https://blogs.microsoft.com/on-the-issues/category/cybersecurity/feed/ |
| Microsoft Security | https://www.microsoft.com/security/blog/feed/ |
| MIT Technology Review | https://www.technologyreview.com/ |
| Naked Security | https://nakedsecurity.sophos.com/feed/ |
| NBC News | https://www.nbcnews.com |
| Netzpolitik | https://netzpolitik.org/ |
| New York Times | https://www.nytimes.com/ |
| New York Times RSS | https://www.nytimes.com/rss |
| News.com | https://www.news.com.au/ |
| NPR | https://www.npr.org |
| Palo Alto Unit42 | https://unit42.paloaltonetworks.com/feed/ |
| Politico | https://www.politico.com |
| Politico EU | https://www.politico.eu/ |
| Politico EU (news) | https://www.politico.eu/news/ |
| Politiken [Ausland] | https://politiken.dk/udland/ |
| Politiken [Inland] | https://politiken.dk/indland/ |
| Postimees | https://news.postimees.ee/#_ga=2.84184540.496198616.1642498310-1308883476.1642498308 |
| ProofPoint | https://www.proofpoint.com/us/blog/threat-insight?page=3 |
| QuoIntelligence | https://quointelligence.eu/blog/ |
| ReadMe by Synack | https://readme.security/ |
| Reaqta | https://reaqta.com/blog |
| Recorded Future Insikt Group | https://www.recordedfuture.com/ |
| Red Alert | https://redalert.nshc.net/blog/feed/ |
| Reuters | https://www.reuters.com/subjects/cybersecurity |
| RFE/RL - Features & Blogs | https://www.rferl.org/api/zmoiiebkii |
| RFE/RL - News | https://www.rferl.org/api/zbqimetkiy |
| RFE/RL - Ukraine Live Blog | https://www.rferl.org/api/zqiimqekgimi |
| RFE/RL - Watchdog | https://www.rferl.org/api/zroiveukiv |
| RSF | https://rsf.org/en |
| Rzeczpospolita [International] | https://www.rp.pl/wydarzenia/swiat |
| Rzeczpospolita [national] | https://www.rp.pl/wydarzenia/kraj |
| Schneier on Security | https://www.schneier.com/feed/ |
| Securelist by Kaspersky | https://securelist.com/category/incidents/feed/ |
| Security Affairs | https://securityaffairs.co/wordpress/feed/ |
| Security Middle East & Africa | https://securitymea.com/category/news/ |
| Security Middle East Magazine | https://www.securitymiddleeastmag.com/category/cyber-security/feed/ |
| SecurityBrief Asia | https://securitybrief.asia/ |
| SecurityWeek | https://feeds.feedburner.com/securityweek |
| Securonix | https://www.securonix.com/blog/ |
| Securonix Blog | https://www.securonix.com/blog/ |
| SentinelOne Blog | https://de.sentinelone.com/blog/ |
| Sky News | https://news.sky.com/ |
| SocRadar | https://socradar.io/blog/ |
| Softpedia News | https://news.softpedia.com/newsRSS/Security-5.xml |
| South China Morning Post | https://www.scmp.com |
| SPIEGEL Online [Ausland] | https://www.spiegel.de/ausland/ |
| SPIEGEL Online [Politik Deutschland] | https://www.spiegel.de/politik/deutschland/ |
| Sud Deutsche | https://www.sueddeutsche.de/ |
| Sydney Morning Herald | https://www.smh.com.au |
| Symantec | https://symantec-enterprise-blogs.security.com/blogs/threat-intelligence |
| Tarnkappe.info | https://tarnkappe.info/ |
| Tech Radar | https://www.techradar.com/ |
| TechCrunch | https://techcrunch.com/ |
| Technology Review | https://www.technologyreview.com/ |
| TechRepublic | https://www.techrepublic.com/rssfeeds/topic/security/ |
| Telegraph (feedsportal) | https://telegraph.feedsportal.com |
| The Atlantic | https://www.theatlantic.com/ |
| The Christian Science Monitor | https://www.csmonitor.com/ |
| The Cipher Brief | https://www.thecipherbrief.com/ |
| The Citizen Lab | https://citizenlab.ca |
| The Daily Swig | https://portswigger.net/daily-swig/rss/ |
| The Diplomat | https://thediplomat.com/ |
| The Guardian | https://www.theguardian.com/uk/technology |
| The Hacker News | https://feeds.feedburner.com/TheHackersNews |
| The Hill | https://www.thehill.com |
| The Intercept | https://theintercept.com |
| The Record | https://therecord.media/feed |
| The Start (Malaysia) | https://www.thestar.com.my/ |
| The Telegraph | https://www.telegraph.co.uk/cyber-attacks/ |
| The Times UK | https://www.thetimes.co.uk/#section-news |
| The Verge | https://www.theverge.com |
| The Washington Post | https://www.washingtonpost.com/ |
| ThreatConnect | https://threatconnect.com/blog/?fwp_blog_topic=threat-research |
| Threatpost | https://threatpost.com/ |
| Time | https://time.com/ |
| Trend Micro | https://www.trendmicro.com/vinfo/us/security/news/ |
| https://twitter.com | |
| USA Today | https://www.usatoday.com/ |
| USA Today (EU) | https://eu.usatoday.com/ |
| Voice of America News | https://www.voanews.com |
| Volexity | https://www.volexity.com/blog/ |
| Volkskrant | https://www.volkskrant.nl |
| Vox | https://www.vox.com |
| Wall Street Journal | https://www.wsj.com/ |
| War on the Rocks | https://warontherocks.com/feed/ |
| Washington Post | https://www.washingtonpost.com |
| Washington Post Feeds | https://feeds.washingtonpost.com |
| WeLiveSecurity | https://www.welivesecurity.com/feed/ |
| Wired | https://www.wired.com/category/security/feed |
| ZDnet | https://www.zdnet.com/ |
| ZeeNews India | https://zeenews.india.com/tags/cyber-security.html |
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15